蒙特卡洛树搜索(英语:Monte Carlo tree search;简称:MCTS)是一种用于某些决策过程的启发式搜索算法,最引人注目的是在游戏中的使用。一个主要例子是电脑围棋程序,它也用于其他棋盘游戏、即时电子游戏以及不确定性游戏。
历史
基于随机抽样的蒙特卡洛方法可以追溯到20世纪40年代。布鲁斯·艾布拉姆森(Bruce Abramson)在他1987年的博士论文中探索了这一想法,称它“展示出了准确、精密、易估、有效可计算以及域独立的特性。”他深入试验了井字棋,然后试验了黑白棋和国际象棋的机器生成的评估函数。1992年,B·布鲁格曼(B. Brügmann)首次将其应用于对弈程序,但他的想法未获得重视。2006年堪称围棋领域蒙特卡洛革命的一年,雷米·库洛姆(Remi Coulom)描述了蒙特卡洛方法在游戏树搜索的应用并命名为蒙特卡洛树搜索。列文特·科奇什(Levente Kocsis)和乔鲍·塞派什瓦里(Csaba Szepesvári)开发了UCT算法,西尔万·热利(Sylvain Gelly)等人在他们的程序MoGo中实现了UCT。2008年,MoGo在九路围棋中达到段位水平,Fuego程序开始在九路围棋中战胜实力强劲的业余棋手。2012年1月,Zen程序在19路围棋上以3:1击败二段棋手约翰·特朗普(John Tromp)。

自2007年以来KGS围棋服务器上最优秀围棋程序的评级。自2006年以来,最优秀的程序全部使用蒙特卡洛树搜索。
蒙特卡洛树搜索也被用于其他棋盘游戏程序,如六贯棋、三宝棋、亚马逊棋和印度斗兽棋;即时电子游戏,如《吃豆小姐》、《神鬼寓言:传奇》、《罗马II:全面战争》;不确定性游戏,如斯卡特、扑克、万智牌、卡坦岛。
原理
蒙特卡洛树搜索的每个循环包括四个步骤:
- 选择(Selection):从根节点R开始,连续向下选择子节点至叶子节点L。下文将给出一种选择子节点的方法,让游戏树向最优的方向扩展,这是蒙特卡洛树搜索的精要所在。
- 扩展(Expansion):除非任意一方的输赢使得游戏在L结束,否则创建一个或多个子节点并选取其中一个节点C。
- 仿真(Simulation):再从节点C开始,用随机策略进行游戏,又称为playout或者rollout。
- 反向传播(Backpropagation):使用随机游戏的结果,更新从C到R的路径上的节点信息。
每一个节点的内容代表胜利次数/游戏次数
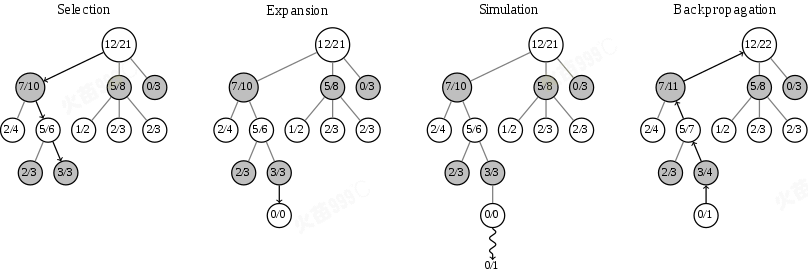
蒙特卡洛树搜索的步骤
探索与利用
选择子结点的主要困难是:在较高平均胜率的移动后,在对深层次变型的利用和对少数模拟移动的探索,这二者中保持某种平衡。第一个在游戏中平衡利用与探索的公式被称为UCT(Upper Confidence Bounds to Trees,上限置信区间算法 ),由匈牙利国家科学院计算机与自动化研究所高级研究员列文特·科奇什与阿尔伯塔大学全职教授乔鲍·塞派什瓦里提出。UCT基于奥尔(Auer)、西萨-比安奇(Cesa-Bianchi)和费舍尔(Fischer)提出的UCB1公式,并首次由马库斯等人应用于多级决策模型(具体为马尔可夫决策过程)。科奇什和塞派什瓦里建议选择游戏树中的每个结点移动,从而使表达式 {\displaystyle {\frac {w_{i}}{n_{i}}}+c{\sqrt {\frac {\ln t}{n_{i}}}}}具有最大值。在该式中:
{\displaystyle w_{i}}代表第{\displaystyle i}次移动后取胜的次数;{\displaystyle n_{i}}代表第{\displaystyle i}次移动后仿真的次数;{\displaystyle c}为探索参数—理论上等于{\displaystyle {\sqrt {2}}};在实际中通常可凭经验选择;{\displaystyle t}代表仿真总次数,等于所有{\displaystyle n_{i}}的和。
目前蒙特卡洛树搜索的实现大多是基于UCT的一些变形。
原文地址:
https://zh.wikipedia.org/wiki/%E8%92%99%E7%89%B9%E5%8D%A1%E6%B4%9B%E6%A0%91%E6%90%9C%E7%B4%A2
在知识共享 署名-相同方式共享 3.0协议之条款下提供